本記事では決定木やその派生形のモデルについて書いてあります。
目次は以下の通りです。
そもそも決定木とは
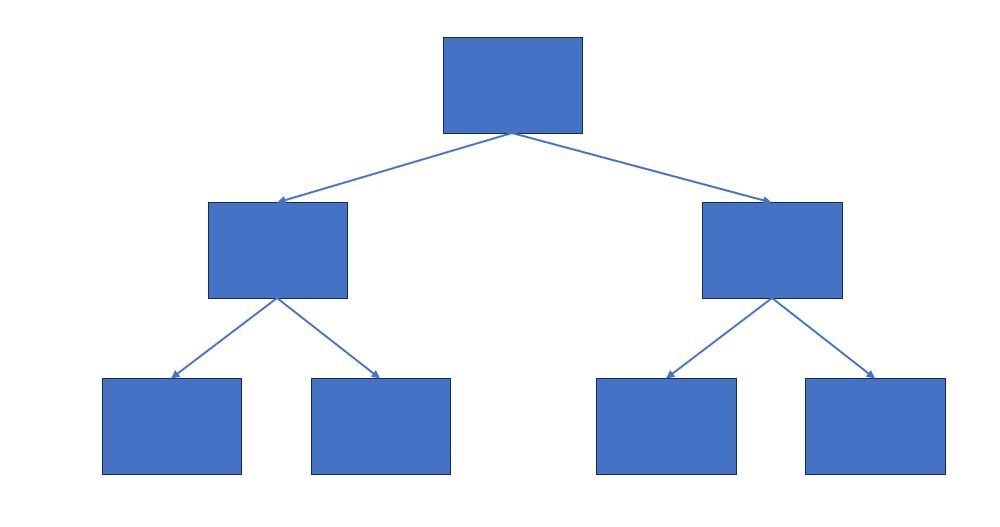
決定木とは樹形図のように条件分岐によりグループに分割しながら、パターンを認識する手法で、教師あり学習の一種です。⾮線形なデータを扱えるモデルであり、回帰でも分類でも対応できるのが特徴です。
決定木のメリット
決定木のメリットは「わかりやすい!」と「伝えやすい!」ということです。
まず、決定木はデータの分割を木の枝とノードで表現します。これにより、どのようにデータが分類または予測されるかを視覚的に理解しやすくなります。各ノードは特定の条件(特徴量の値の範囲や閾値)に基づいてデータを分割し、枝が分岐していく構造は直感的で可視化しやすいです。
また、決定木は分割の過程が一連の質問として表現できます。例えば、ある商品をクラス分けする場合、最初の質問は「価格が〇〇円未満か?」といった形であり、これをたどることでクラスが決定されます。このような質問の連鎖を追いながら、結果を理解するのが容易です。
さらに、各ノードにおける分割条件とその条件に基づくデータ数やクラスの分布などが表示できるため、モデルの動作や特徴量の重要性の解釈がしやすく、データの傾向やパターンを探るのに役立ちます。この可視化と直感的な理解は、意思決定や問題解決において非常に有用であり、決定木の利点の一つと言えます。
決定木のデメリット
一方、最大のデメリットとして挙げられるのは過学習しやすい点です。
決定木は基本的に訓練データに完全に適合しようとするため、ツリーを深く分割することがあります。これにより、ノイズや個々のデータポイントに過剰に適応し、訓練データに対する予測性能は高まります。しかし、この過度の適合は新しいデータに対する一般化能力を低下させ、過学習が発生します。
なので、過学習抑制のために考案されたモデルがいくつかあるので紹介します。
アンサンブル学習器
アンサンブル学習器とは過学習抑制のため手法の一つで、単独では精度が高くない単純モデルを複数作って、組み合わせてから使うことで精度を改善する手法です。まさしく一人では難しいけど、みんなで力を合わせよう!っていう感じですね。
アンサンブル学習器の代表例として挙げられるものがランダムフォレストと勾配ブースティングです。この2つについて簡単に解説していきます
ランダムフォレスト
ランダムフォレストは、複数の決定木を並列に学習させ、それぞれの木が予測を行った後、最終的な出力を多数決や平均によって決定する手法です。この手法は、複数の単純な決定木が一つの結果を出す概念で、まるで森ができているようなイメージを持っています。複数の決定木が個別に予測を行い、その結果を集計し、多数決で最終的な出力値を決めることが特徴です。ランダムフォレストのメリットは、高い汎化性能を持ち、並列処理が可能であるため、高速に計算できる点にあります。
勾配ブースティング
勾配ブースティングは弱学習器を順番に訓練し、前のモデルの誤差に焦点を当てて性能を向上させる強力なアンサンブル学習手法です。
これはブースティングの代表例で、弱い決定木を順番に訓練し、前のモデルの誤差に焦点を当てて学習を進め、最終的に強力なモデルを得ます。
以下は、ランダムフォレストと勾配ブースティングのメリットとデメリットをまとめた表です。
| ランダムフォレスト | 勾配ブースティング | |
| メリット | ・汎化性能が高い ・高速に計算できる | ・高精度 |
| デメリット | ・学習データの量で精度が変わる | ・時間がかかる |
まとめ
本記事では決定木の基本と過学習抑制のために用いられるアンサンブル学習やランダムフォレストについて記しました。

コメント